爬取微信公众号小结
前言
一直想爬微信公众号然后整成一个bot。试过好几次
最终都以失败告终。昨天折腾了一晚上,利用搜狗的微信爬取弄好了
爬取的方法
网上能搜到的爬取方法:
- 微信公众号平台接口抓取|限制:微信KEY有限制,30-40分钟内就会过期。请求次数超过10-20次被封
- 搜狗公众号爬取 | 缺陷:只能获取公众号最新更新的一条文章
爬取实现
这里是用第二种方法,方法如下
搜狗微信公众号搜索对应公众号:https://weixin.sogou.com/weixin?type=1&query=bibacps&ie=utf8
获取文章链接
然后请求这个链接得到wx文章的链接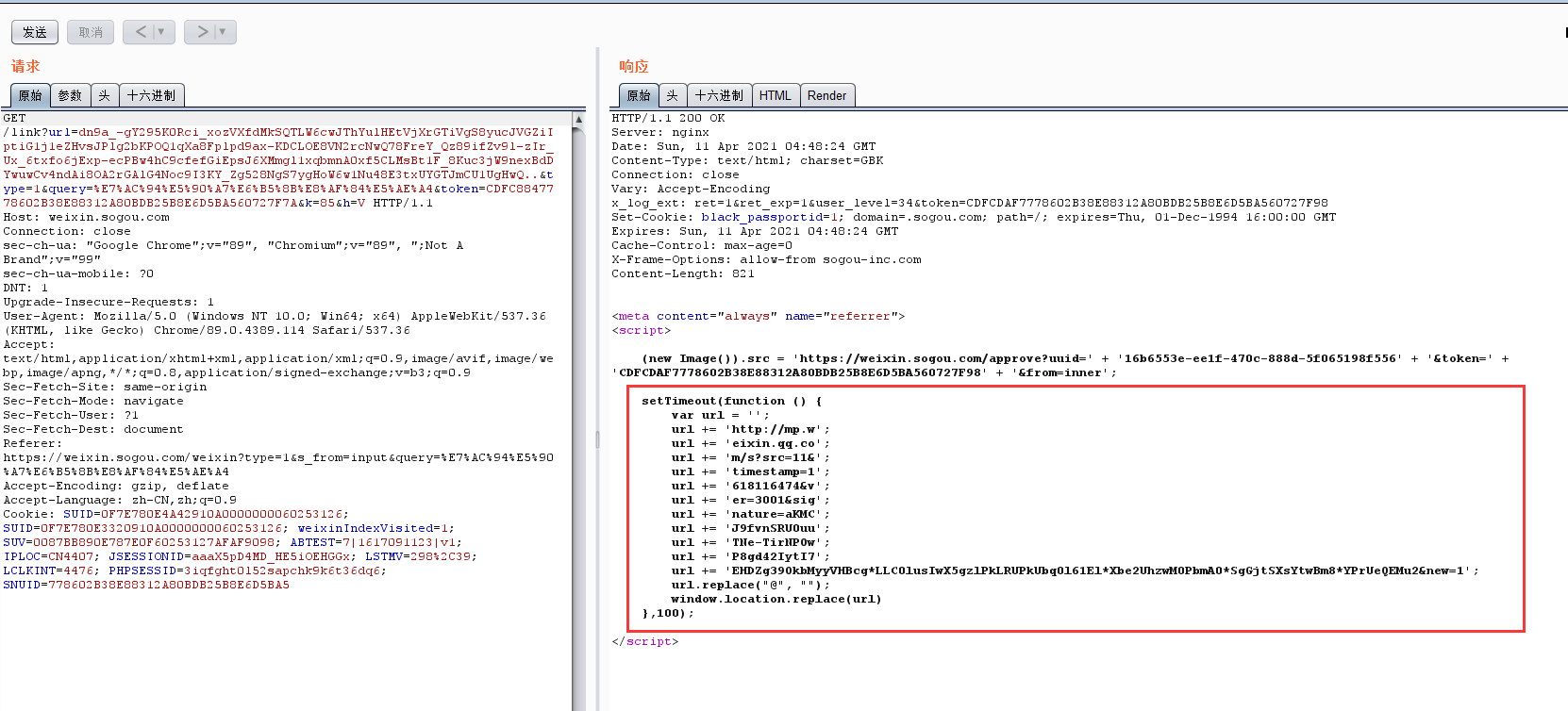
经过测试,发现并无cookie等效验。访问https://weixin.sogou.com/<sougou_wx_lnk>就可以获取wx文章url。但是,请求次数太多就会出现验证码,只有cookie对了才不会有验证码
google后得到解决方法:
- 随机UA头
- 每次请求之前先获取搜狗子域名cookie
参考链接:https://blog.csdn.net/weixin_43881394/article/details/107768458
获取子域名cookie
import requests
def getcookie():
#从搜狗视频获取cookie,防止傻逼搜狗机制检测
url = 'https://v.sogou.com/v?ie=utf8&query=&p=40030600'
headers = {'User-Agent': UserAgent().random}
rst = requests.get(url=url,headers=headers,allow_redirects=False)
cookies = rst.cookies.get_dict()
return cookies
爬取到wx文章链接后入库
最终效果如下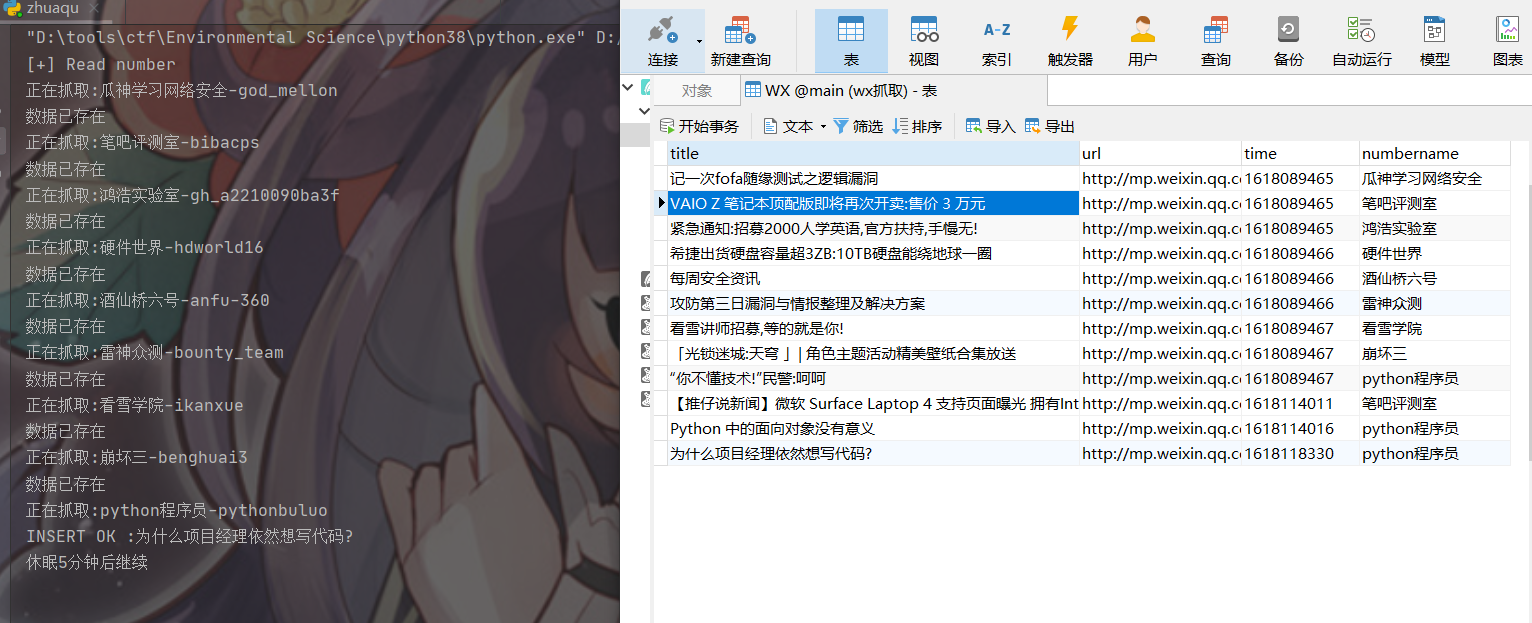
爬虫小技巧
爬取大型站点(例如:google.com)
可能会遇到的问题:
* 请求次数过多导致验证码
* Cookie判断是否多次请求
解决发方法
* 随机IP代理
* 随机UA头
* SESSION请求
* 针对Cookie判断是否多次请求 (这种大型站点cookie生成机制都是一致的,可以请求这种站点的子域名获取cookie。每次请求之前,先从子域名获取cookie然后在用这个cookie请求要爬取的站点)
* 延时请求
遇见CSRF TOKEN效验
* TOKEN效验
* COOKIE效验
解决方法:
* 这种CRSF TOKEN一般在当前页面存在TOKEN,先获取TOKEN在去请求
指定某个地区的IP请求
解决方法:
* 使用对应地区的IP请求
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。
文章标题:爬取微信公众号小结
本文作者:九世
发布时间:2021-04-11, 12:36:54
最后更新:2021-04-11, 13:23:45
原始链接:http://jiushill.github.io/posts/3dedb035.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。