抓取sploitus的记录
前言
上学的第二个星期回到家,在这个星期翻到一个不错的搜索引擎。果断将其爬下来
💀 Sploitus | Exploit & Hacktool Search Engine
Music:
正文
首先请求URL然后抓包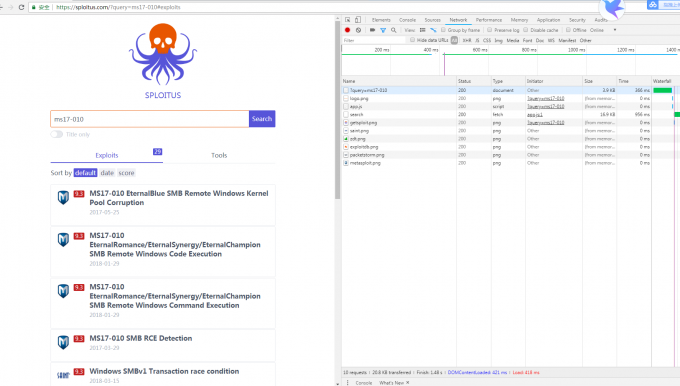
逐个观察,发现search返回了搜索的内容那么就看他了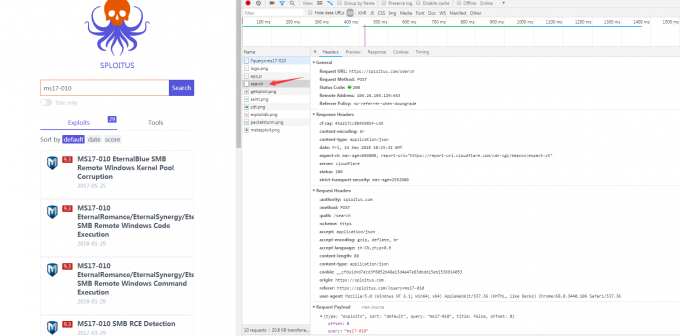
返回是json
爬虫思路:发现有accept: application/json请求头,那么就很简单了
带上user-agent头和accept头和对应的请求参数post请求格式化json即可
代码:
import requests
banner='''
.dMMMb dMMMMb dMP .aMMMb dMP dMMMMMMP dMP dMP .dMMMb
dMP" VP dMP.dMP dMP dMP"dMP amr dMP dMP dMP dMP" VP
VMMMb dMMMMP" dMP dMP dMP dMP dMP dMP dMP VMMMb
dP .dMP dMP dMP dMP.aMP dMP dMP dMP.aMP dP .dMP
VMMMP" dMP dMMMMMP VMMMP" dMP dMP VMMMP" VMMMP"
'''
print(banner)
print('')
print('author:Nine world')
print('--------------------------------------------------------------------------------------')
def sploitus():
#headers={'user-agent':'User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36','content-type': 'application/json','accept': 'application/json','referer': 'https://sploitus.com/?query=MS17-010'}
print('[!] Please select type')
print('exploits')
print('tools')
xz=input('type:')
user=input('query:')
print('')
headers={
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
url='https://sploitus.com/search'
data={'offset':0,'query':"{}".format(user),'sort':"default",'title':'false','type':"{}".format(xz)}
cookie={'__cfduid':'d7ecd3f6052b48a13d4a47e83dbdd15eb1536914053'}
requt=requests.post(url=url,headers=headers,json=data,cookies=cookie)
jds=requt.json()
lp=jds['exploits'][0:]
for l in lp:
print('title:',l['title'])
#print('published',l['published'])
print('id',l['id'])
print('type:',l['type'])
print('url:',l['href'])
print('')
sploitus()
测试截图: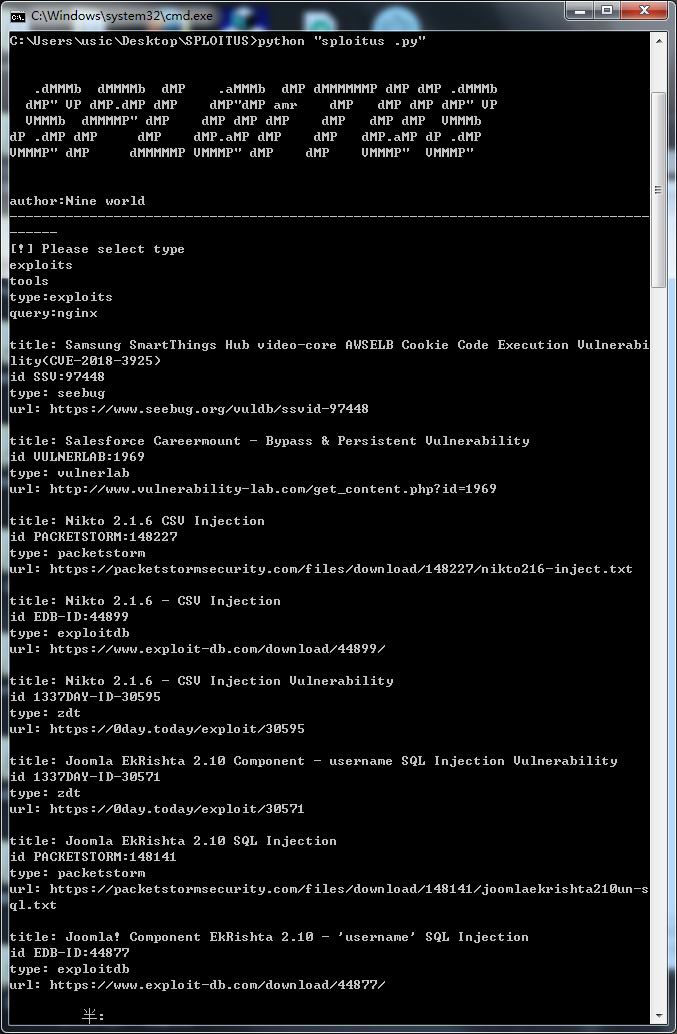
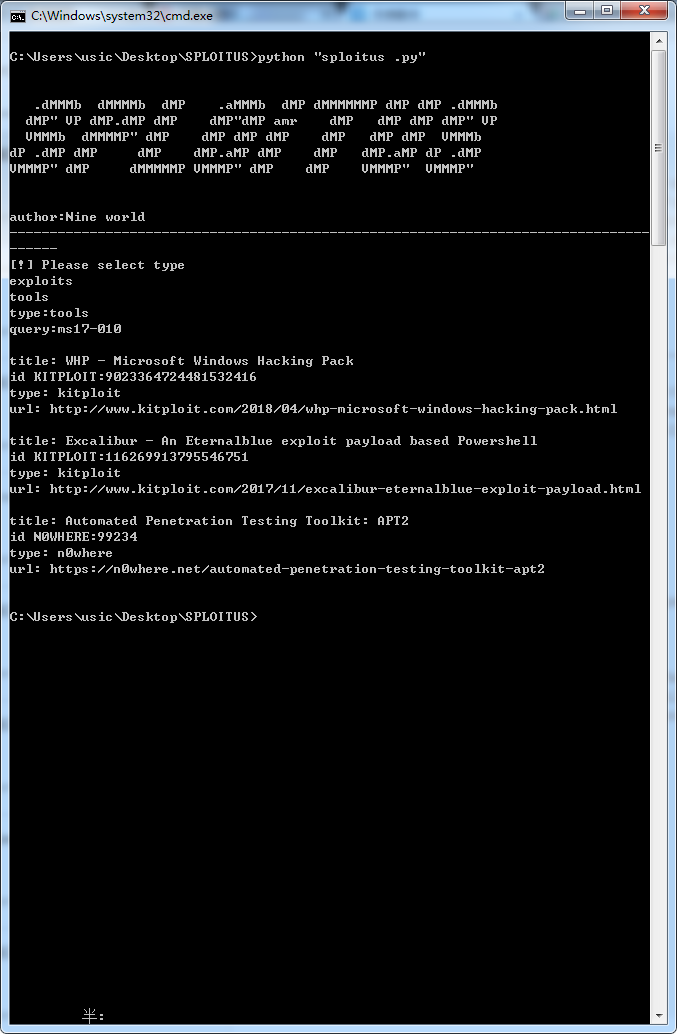
转载请注明:转自422926799.github.io
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。
文章标题:抓取sploitus的记录
本文作者:九世
发布时间:2018-09-14, 18:07:01
最后更新:2019-04-19, 20:36:16
原始链接:http://jiushill.github.io/posts/b2d37895.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。